
Google has unveiled Gemini 3.1 Pro, an upgrade to the Gemini 3 series that, according to the company, represents a major leap in problem-solving capabilities. The model is being rolled out immediately in preview mode for developers, enterprises, and end users.
Gemini 3.1 Pro is designed for tasks “where a simple answer is not enough,” the Gemini team writes in its official blog post. Google describes the model as the enhanced foundational intelligence that also underpins the breakthroughs seen in Gemini 3 Deep Think, which was updated just a week earlier. While Deep Think targets highly complex problems in science, research, and engineering, 3.1 Pro is meant to bring those advances into everyday applications
More Than Double the Reasoning Performance on ARC-AGI-2
The most striking improvement appears on the ARC-AGI-2 benchmark, which measures abstract reasoning. According to Google, Gemini 3.1 Pro achieves 77.1%, more than double the 31.1% score of Gemini 3 Pro. This places it ahead of Anthropic’s Opus 4.6 (68.8%) and OpenAI’s GPT-5.2 (52.9%).
That said, even higher scores have been achieved by other AI systems in the past—without fundamentally reshaping the AI landscape—highlighting the limits of benchmark-driven comparisons.
Google also reports strong results across several other benchmarks. On GPQA Diamond, which tests scientific knowledge, Gemini 3.1 Pro scores 94.3%. On SWE-Bench Verified, focused on agentic coding tasks, it reaches 80.6%, nearly matching Opus 4.6 at 80.8%. Additional agentic benchmarks show similarly strong performance, including MCP Atlas (69.2%) and BrowseComp (85.9%).
On LiveCodeBench Pro, a competitive coding benchmark, the model achieves an Elo score of 2887, outperforming both Gemini 3 Pro (2439) and GPT-5.2 (2393).
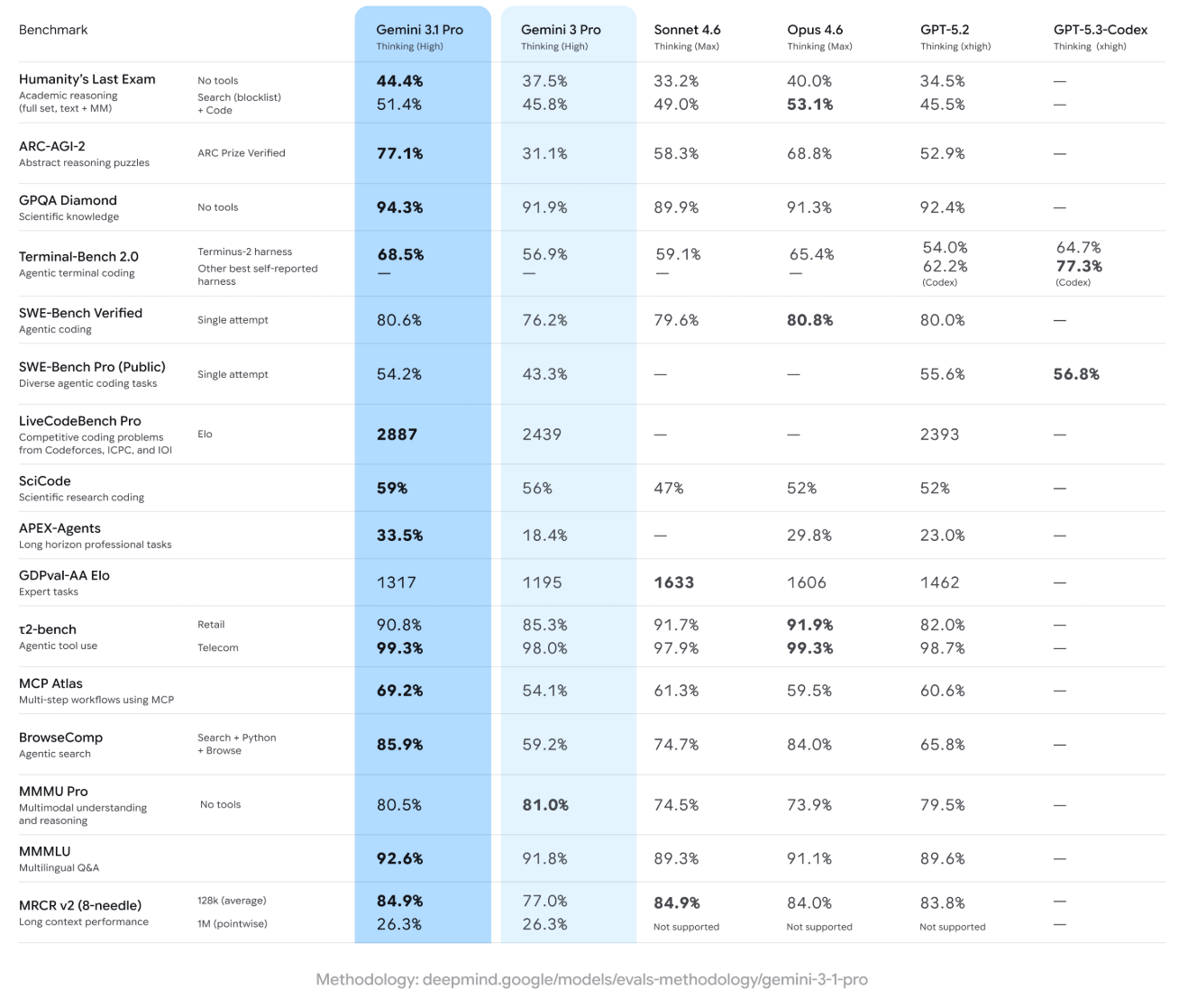
Still, Gemini 3.1 Pro does not lead across the board. On the multimodal MMMU Pro benchmark, the previous Gemini 3 Pro slightly outperforms it (81.0% vs. 80.5%). Meanwhile, on Humanity’s Last Exam with tool support, Anthropic’s Opus 4.6 takes the lead with 53.1%.
A recurring criticism of Google’s recent models remains their less efficient use of tools compared with OpenAI’s and Anthropic’s systems.
As always, benchmarks offer only limited insight into real-world performance—especially for incremental updates like the transition from 3.0 to 3.1. Google itself suggests that the best way to evaluate the model is by testing it with familiar prompts where expectations and prior outputs are well understood.
From Advanced Reasoning to Practical Applications
According to Google, Gemini 3.1 Pro uses advanced reasoning to bridge the gap between complex APIs and user-friendly design. One concrete example cited is a live aerospace dashboard, where the model independently configured a public telemetry stream to visualize the orbit of the International Space Station.
Another example is the ability to generate animated SVGs directly from text prompts, ready for embedding on websites—or even to create entire websites outright. In other words, tasks that are fundamentally solved through code.
Broad Availability and Tiered Pricing
Google is rolling out Gemini 3.1 Pro across multiple platforms simultaneously. Developers can access it via the Gemini API in Google AI Studio, Gemini CLI, the agentic development platform Google Antigravity, and Android Studio. Enterprises can use the model through Vertex AI and Gemini Enterprise. End users will gain access via the Gemini app and NotebookLM, with the latter reserved for Pro and Ultra subscribers.
API pricing mirrors that of Gemini 3 Pro and scales with prompt length. Compared with Anthropic’s Opus models, Gemini remains significantly cheaper.
Pricing (API)
-
Up to 200,000 tokens
-
Input: $2.00 / 1M tokens
-
Output: $12.00 / 1M tokens
-
Caching: $0.20 / 1M tokens
-
-
Over 200,000 tokens
-
Input: $4.00 / 1M tokens
-
Output: $18.00 / 1M tokens
-
Caching: $0.40 / 1M tokens
-
-
Cache storage: $4.50 / 1M tokens per hour
-
Search: 5,000 prompts/month free, then $14.00 / 1,000 requests
However, Gemini 3.1 Pro is still in preview. Google plans to refine the model further based on user feedback—particularly for “ambitious agentic workflows”—before moving to full general availability.

 ES
ES  EN
EN