

Los motores de búsqueda basados en IA se enfrentan a un reto técnico fundamental: antes de que un modelo de lenguaje pueda generar una respuesta, primero debe reducir miles de millones de páginas web a un pequeño conjunto de documentos relevantes.
Este primer paso de filtrado lo realizan los llamados modelos de embeddings. Estos convierten consultas y documentos en vectores numéricos, lo que permite calcular matemáticamente la similitud semántica. Qué documentos se transfieren a los modelos de ranking y a los modelos de lenguaje posteriores depende directamente de la calidad de estos embeddings.
Perplexity ha lanzado ahora dos modelos propios de embeddings: pplx-embed-v1 y pplx-embed-context-v1. El primero está diseñado para la recuperación clásica de texto denso, mientras que el segundo incrusta los fragmentos de texto dentro del contexto del documento circundante, lo que ayuda a resolver pasajes ambiguos. Ambos modelos están disponibles en variantes de 0,6 mil millones y 4 mil millones de parámetros.

Según Perplexity, sus modelos logran resultados en el benchmark MTEB comparables a los embeddings Qwen3 de Alibaba y Gemini de Google, al tiempo que almacenan significativamente más páginas por gigabyte gracias a una cuantización agresiva.
Comprensión bidireccional del texto en lugar de procesamiento unidireccional
La mayoría de los principales modelos de embeddings se basan en grandes modelos de lenguaje que procesan el texto solo en una dirección, de izquierda a derecha. Cada palabra solo puede “ver” las palabras anteriores, no las posteriores. Aunque esto es adecuado para la generación de texto, limita la comprensión, ya que el significado de una frase suele depender del contexto completo.
Perplexity adopta un enfoque diferente. Sus modelos se construyen sobre los modelos de lenguaje Qwen3 preentrenados de Alibaba, que originalmente procesan el texto de izquierda a derecha. Los investigadores modifican estos modelos para que puedan leer el texto de forma bidireccional.
Posteriormente aplican un procedimiento de entrenamiento con tokens enmascarados similar al de BERT de Google: se ocultan palabras aleatoriamente dentro de los textos y el modelo debe inferir los elementos faltantes utilizando el contexto en ambas direcciones. Los investigadores denominan este enfoque preentrenamiento por difusión.
El entrenamiento se realizó sobre aproximadamente 250 mil millones de tokens en 30 idiomas. La mitad de los datos proviene de sitios educativos en inglés del conjunto FineWebEdu, mientras que la otra mitad cubre 29 idiomas adicionales de FineWeb2. Los estudios de ablación muestran que este enfoque mejoró el rendimiento en tareas de recuperación en alrededor de un punto porcentual.
Otra diferencia práctica es que, según Perplexity, los modelos pplx-embed no requieren prefijos específicos de tarea añadidos a las entradas, un requisito común en modelos competidores. Dichos prefijos pueden degradar la calidad de búsqueda si difieren entre el momento de indexación y el de consulta.
Reducción del consumo de memoria hasta 32×
Almacenar vectores de embeddings para miles de millones de páginas web se vuelve rápidamente costoso. La práctica estándar utiliza valores de coma flotante de 32 bits (FP32). Perplexity, en cambio, entrena sus modelos desde el inicio para operar con enteros de 8 bits (INT8), lo que reduce el uso de memoria en un factor de cuatro sin sacrificar rendimiento.
En una variante aún más compacta binaria, que utiliza solo un bit por valor, el consumo de memoria se reduce hasta 32 veces. En el modelo de 4B, la pérdida de calidad se mantiene por debajo de 1,6 puntos porcentuales, ya que su vector de embeddings más grande (2.560 dimensiones) conserva más información que las 1.024 dimensiones del modelo más pequeño.
Los benchmarks públicos muestran paridad —o liderazgo
En el benchmark MTEB multilingüe (v2), pplx-embed-v1-4B alcanza un nDCG@10 del 69,66%, igualando a Qwen3-Embedding-4B de Alibaba (69,60%) y superando a gemini-embedding-001 de Google (67,71%) con requisitos de memoria mucho menores.
En recuperación contextual, pplx-embed-context-v1-4B establece un nuevo récord en el benchmark ConTEB con 81,96%, frente al 79,45% de voyage-context-3 de Voyage y el 72,40% del modelo contextual de Anthropic.
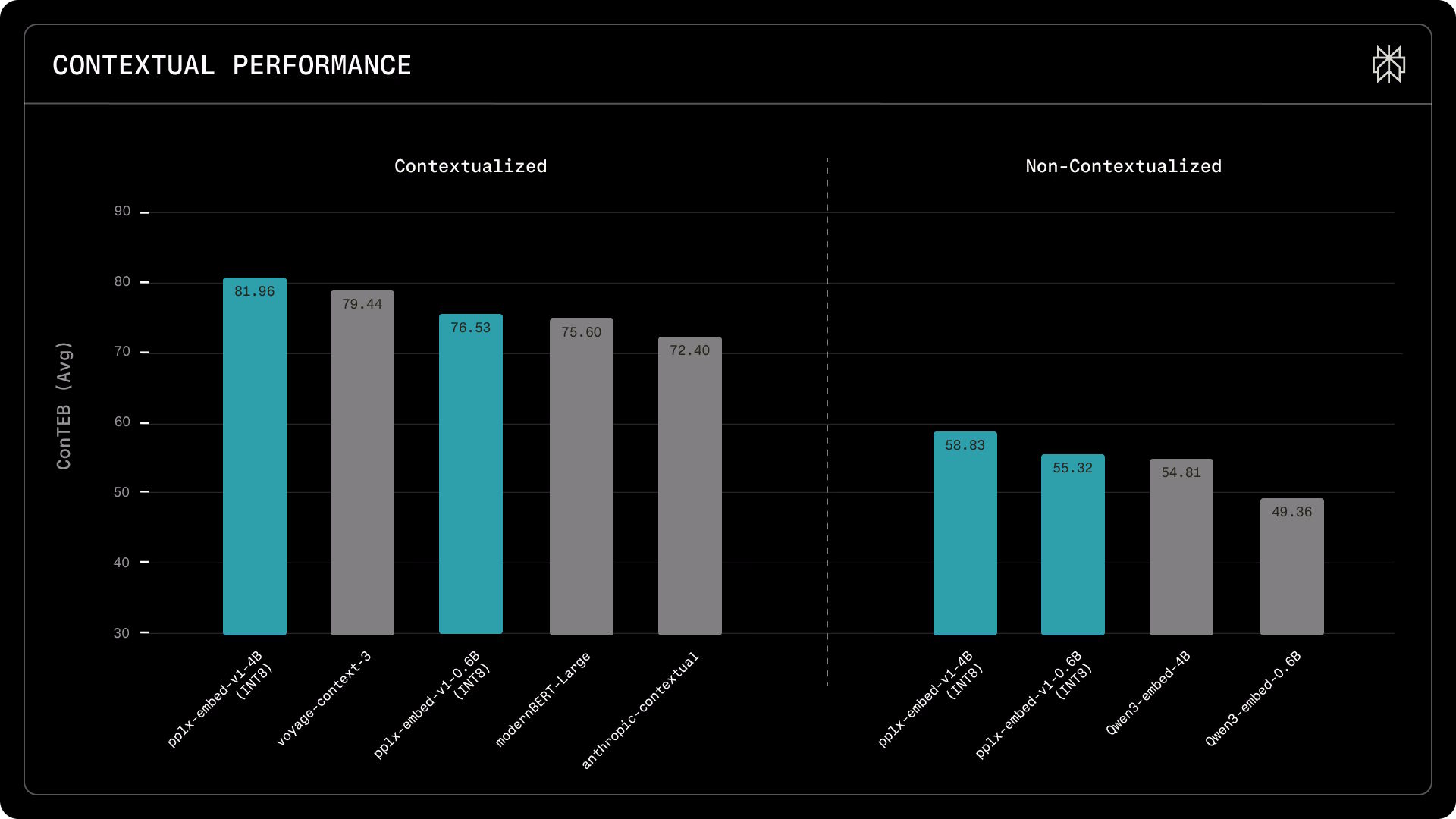
En el benchmark BERGEN, que evalúa el rendimiento end-to-end en escenarios RAG desde la recuperación de documentos hasta la generación de respuestas, el modelo más pequeño pplx-embed-v1-0.6B supera al mucho más grande Qwen3-Embedding-4B en tres de cinco tareas, lo que lo convierte en una opción atractiva para aplicaciones sensibles a la latencia y al coste.
Los benchmarks internos muestran diferencias mayores
Perplexity sostiene que los benchmarks públicos solo reflejan parcialmente la búsqueda web real, ya que a menudo carecen de documentos ruidosos, consultas inusuales y cambios de distribución. Para abordar esto, la empresa desarrolló dos benchmarks internos utilizando hasta 115.000 consultas reales contra más de 30 millones de documentos extraídos de más de mil millones de páginas web.
En el benchmark PPLXQuery2Query, que mide si los modelos reconocen consultas semánticamente equivalentes, pplx-embed-v1-4B logra un Recall@10 del 73,5%, frente al 67,9% de Qwen3-Embedding-4B. El modelo de 0,6B alcanza 71,1%, superando ampliamente a Qwen3-Embedding-0.6B (55,1%) y BGE-M3 (61,8%).
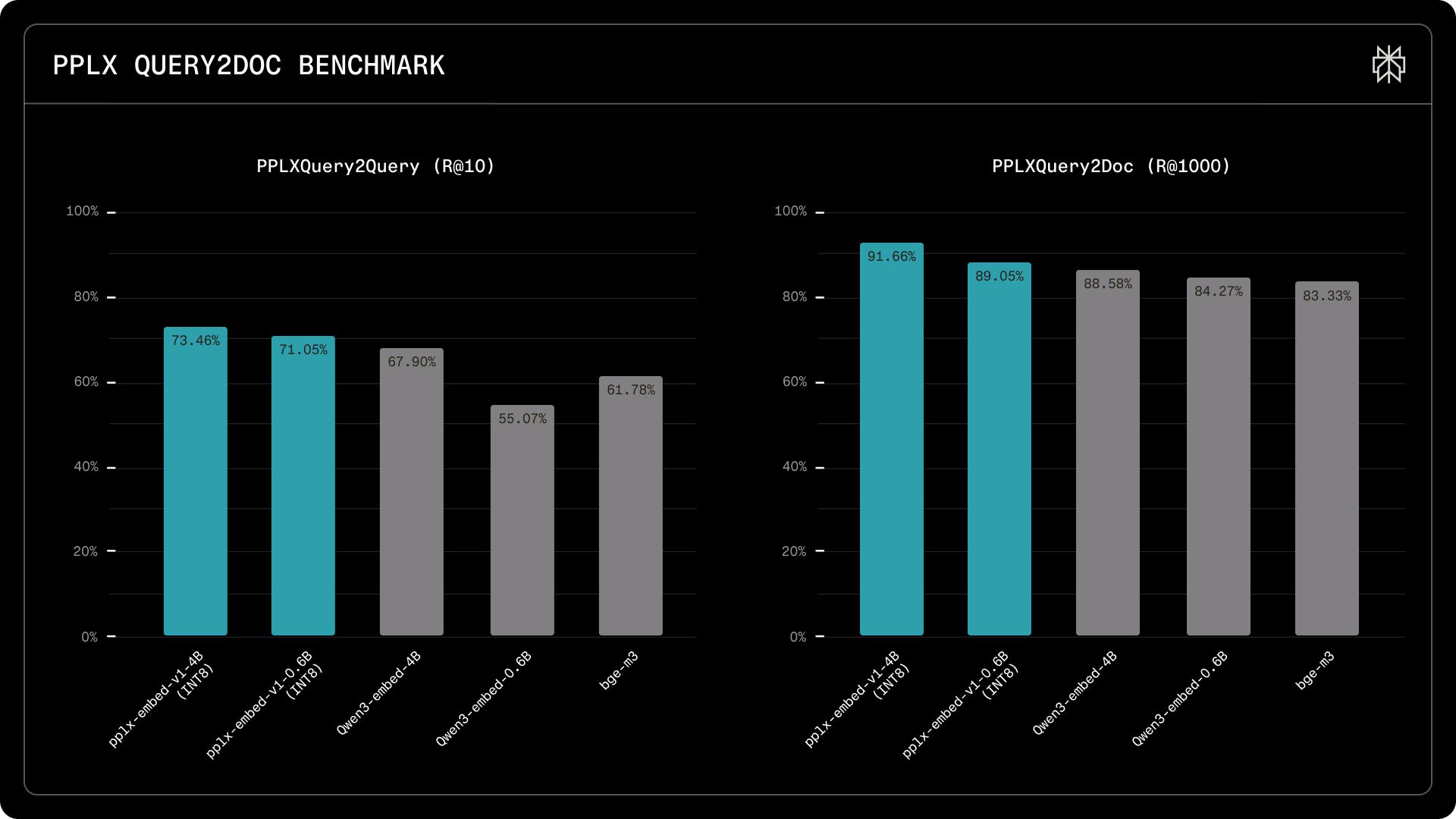
En el benchmark PPLXQuery2Doc, que evalúa la recuperación de documentos en un corpus de 30 millones de páginas, el modelo de 4B recupera el 91,7% de los documentos relevantes dentro de los primeros 1.000 resultados, frente al 88,6% de Qwen3.
Según Perplexity, el objetivo principal de los modelos de embeddings como primera capa de filtrado es recuperar la mayor cantidad posible de documentos relevantes; todo lo que no se encuentre en esta etapa inicial no podrá ser recuperado por los modelos de ranking posteriores.
Los cuatro modelos están disponibles en Hugging Face bajo licencia MIT y pueden utilizarse a través de la API de Perplexity, así como mediante frameworks de inferencia comunes como Transformers, SentenceTransformers y ONNX. La compañía también ha publicado un informe técnico con los resultados completos de la evaluación.

 ES
ES  EN
EN