

Según la compañía, GPT-5.5 está diseñado para comprender solicitudes complejas, utilizar herramientas, verificar sus propios resultados y completar una mayor variedad de tareas de principio a fin.
El modelo puede interpretar la intención del usuario, planificar flujos de trabajo de forma autónoma y llevar tareas de varios pasos hasta un resultado final. OpenAI afirma que GPT-5.5 destaca especialmente en programación, depuración de código, búsqueda de información en internet, análisis de datos, creación de documentos y hojas de cálculo, manejo de software y cambio entre distintas herramientas.
“En lugar de supervisar cuidadosamente cada paso, puedes asignar a GPT-5.5 una tarea compleja de varias etapas y confiar en que planifique, use herramientas, revise su trabajo, gestione la ambigüedad y continúe avanzando”, señaló OpenAI en su anuncio.
OpenAI destacó varias áreas en las que el nuevo modelo resulta especialmente eficaz, como la programación agéntica, el control de computadoras, el trabajo intelectual y la investigación científica en etapas iniciales. Son tareas que suelen requerir largas cadenas de razonamiento, uso de herramientas y toma de decisiones.
“GPT-5.5 ofrece un salto en inteligencia sin sacrificar velocidad. Los modelos más grandes y potentes suelen ser más lentos, pero GPT-5.5 iguala a GPT-5.4 en latencia real por token, al tiempo que demuestra un nivel de inteligencia mucho más alto”, afirmó la compañía.
Según OpenAI, el modelo también utiliza significativamente menos tokens cuando trabaja dentro de Codex.
Antes del lanzamiento, OpenAI aseguró que aplicó su proceso de seguridad más avanzado hasta la fecha, en colaboración con equipos internos y especialistas externos.
Disponibilidad
GPT-5.5 está disponible en ChatGPT y Codex para usuarios de los planes Plus, Pro, Business y Enterprise. Una versión separada, GPT-5.5 Pro, está disponible para usuarios de Pro, Business y Enterprise.
Ambas versiones llegarán próximamente a la API. El precio anunciado es de 5 dólares por 1 millón de tokens de entrada y 30 dólares por 1 millón de tokens de salida. El modelo admite una ventana de contexto de hasta 1 millón de tokens.
En Codex, GPT-5.5 está disponible para los planes Plus, Pro, Business, Enterprise, Edu y Go, con una ventana de contexto de 400.000 tokens. También se ofrece en modo Fast, donde genera tokens 1,5 veces más rápido con un coste 2,5 veces superior.
GPT-5.5 es más caro que GPT-5.4, algo que OpenAI atribuye a su mayor eficiencia en el uso de tokens y a su rendimiento superior.
Qué puede hacer GPT-5.5
OpenAI sostiene que GPT-5.5 utiliza menos tokens y necesita menos reintentos al resolver tareas difíciles. En el índice de programación de Artificial Analysis, el modelo alcanza, según la compañía, un nivel de inteligencia de frontera con aproximadamente la mitad del coste frente a modelos competidores.
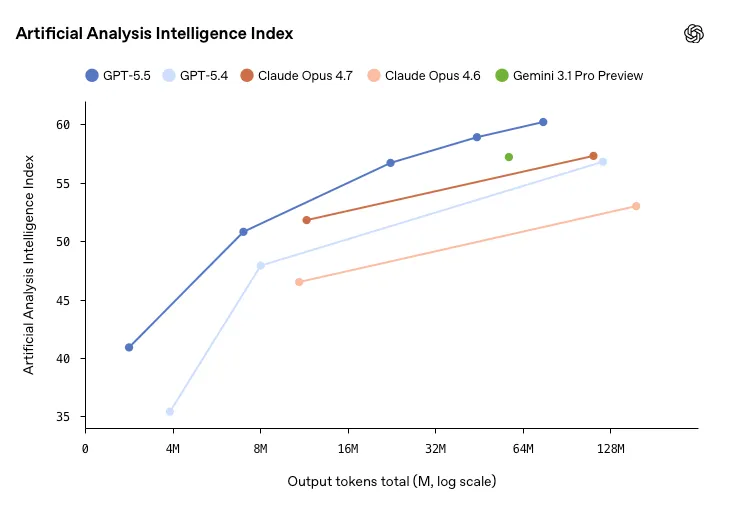
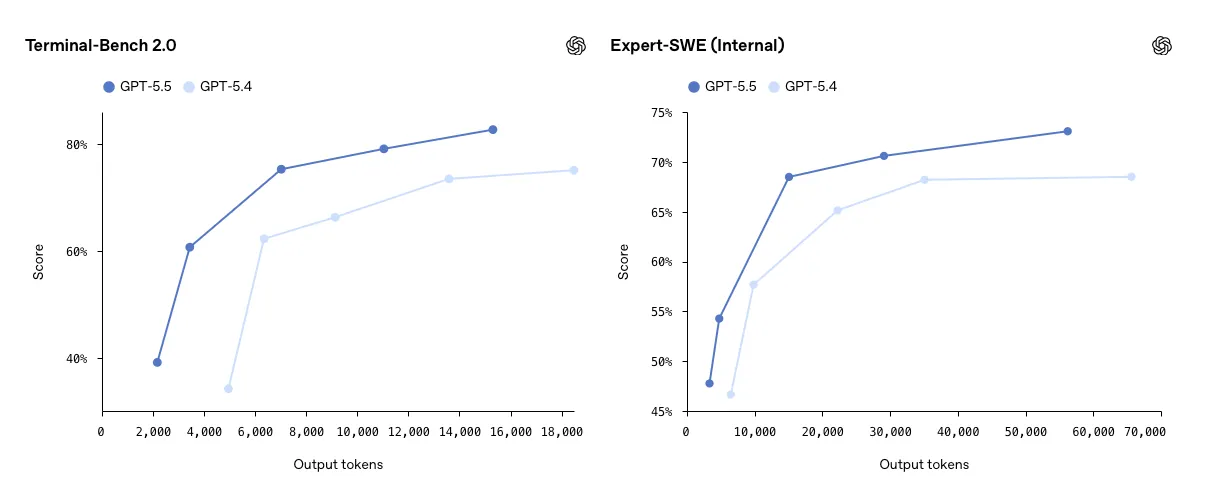
GPT-5.5 es el modelo más capaz de OpenAI para ingeniería de software agéntica. En Terminal-Bench 2.0, un benchmark centrado en flujos de trabajo complejos desde la línea de comandos, el modelo alcanzó una precisión del 82,7%.
También obtuvo un 58,6% en SWE-Bench Pro y superó a GPT-5.4 en Expert-SWE. En los tres benchmarks, GPT-5.5 superó a su predecesor utilizando menos tokens.
“Las fortalezas del modelo en programación se aprecian especialmente en Codex, donde puede encargarse de tareas de ingeniería que van desde la implementación y la refactorización hasta la depuración, las pruebas y la validación”, indicó OpenAI.
GPT-5.5 también comprende mejor cómo funcionan los sistemas. Puede identificar por qué algo falla, determinar dónde deben realizarse los cambios y entender qué partes de una base de código podrían verse afectadas.
OpenAI afirma que el modelo supera notablemente a GPT-5.4 y Claude Opus 4.7 en razonamiento y autonomía. Puede detectar problemas con antelación, anticipar necesidades de pruebas y reconocer cuándo una revisión de código puede ser necesaria sin instrucciones explícitas.
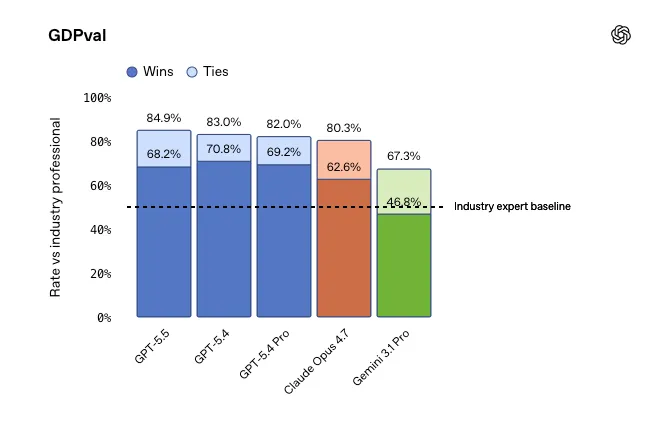
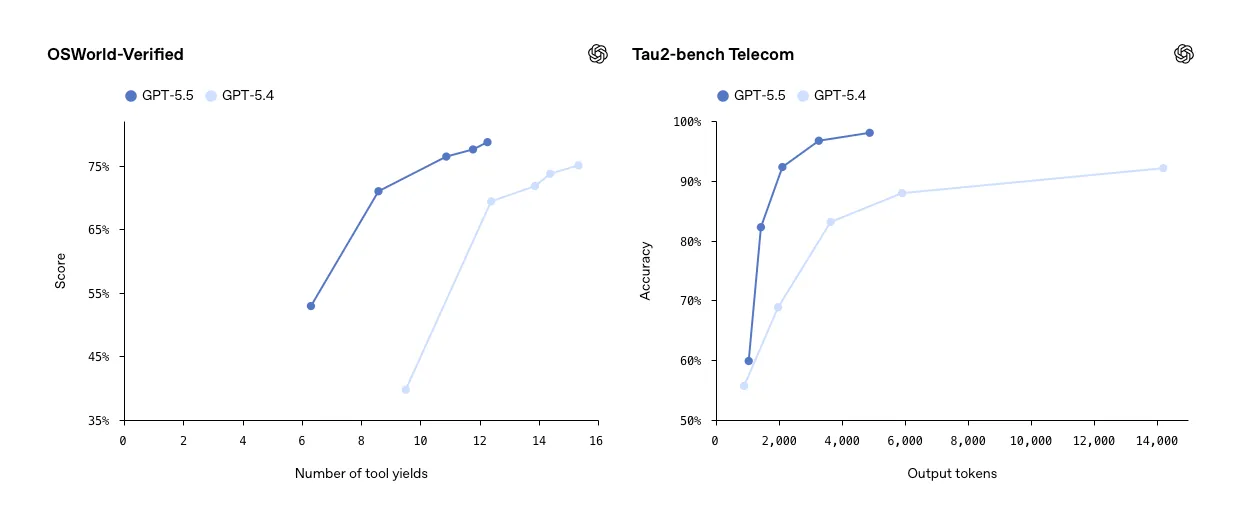
En GDPval, un benchmark que evalúa agentes en tareas de trabajo intelectual claramente definidas en 44 profesiones, GPT-5.5 obtuvo un 84,9%. Además, alcanzó un 78,7% en OSWorld-Verified y un 98% en Tau2-bench.
El modelo también registró resultados sólidos en otros benchmarks profesionales, incluidos un 60% en FinanceAgent, un 88,5% en tareas internas de modelado de banca de inversión y un 54,1% en OfficeQA Pro.
Trabajo con información
OpenAI describe GPT-5.5 como una herramienta potente para el trabajo diario con computadoras. El modelo está diseñado para comprender mejor lo que busca el usuario y gestionar todo el ciclo de trabajo con información: buscar, analizar, usar herramientas, comprobar resultados y convertir datos iniciales en un resultado terminado.
Dentro de Codex, GPT-5.5 supera a GPT-5.4 en la creación de documentos, hojas de cálculo y presentaciones.
OpenAI también señaló que más del 85% de sus empleados, repartidos en distintos departamentos, utiliza Codex cada semana. Esto incluye equipos de ingeniería de software, finanzas, comunicación, marketing, análisis de datos y gestión de producto.
Investigación científica
GPT-5.5 también muestra mejores resultados en flujos de trabajo científicos y técnicos. Estas tareas suelen ir más allá de responder a una pregunta concreta: el modelo debe explorar una idea, reunir evidencias, comprobar una hipótesis e interpretar los resultados.
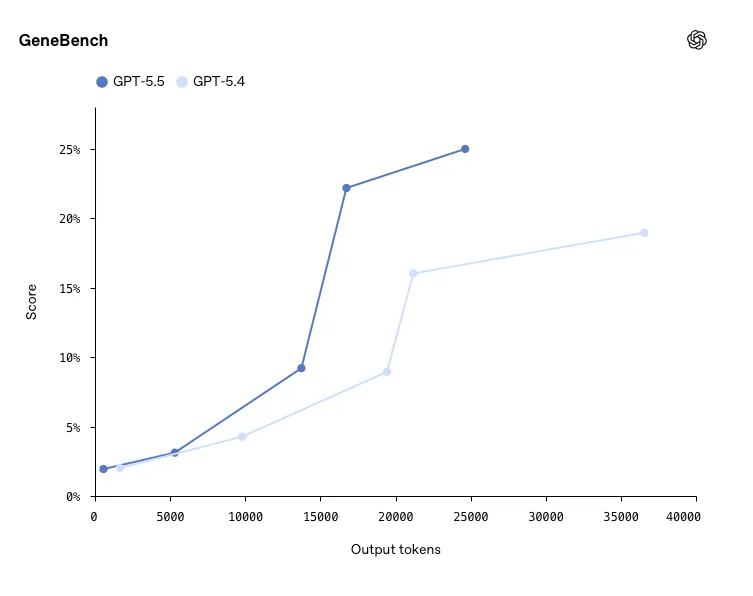
En GeneBench, una plataforma para el análisis científico de datos en varias etapas en genética y biología cuantitativa, GPT-5.5 mejoró los resultados de GPT-5.4.
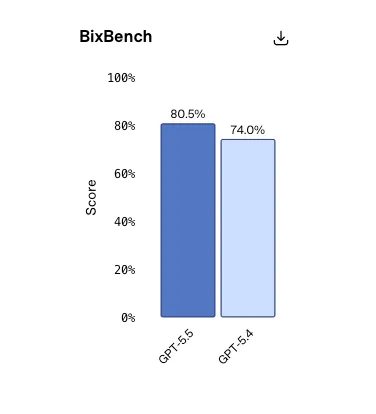
El nuevo modelo también superó a su predecesor en BixBench.
GPT-5.5 refleja el avance de OpenAI hacia sistemas de inteligencia artificial más autónomos, capaces de gestionar flujos de trabajo complejos con menos supervisión humana. Para el público hispanohablante, el punto clave no es solo que el modelo sea “más inteligente”, sino que se presenta como un agente práctico para programación, investigación, productividad de oficina y automatización empresarial.
El lanzamiento llega después de que OpenAI presentara en abril los agentes para espacios de trabajo en ChatGPT, que permiten a los equipos crear asistentes compartidos para tareas complejas y procesos de larga duración.

 ES
ES  EN
EN